偽のReddit投稿がAI回答を乗っ取る?データ汚染の実態
AIに質問すると、偽のReddit投稿を引用することがある。データポイズニング攻撃が大規模言語モデルを汚染している。一般の人はどう対応すべきか。
あなたのAIアシスタントが「毒の餌」を食べているかもしれない
最近、ChatGPTやGeminiなどのAIアシスタントに具体的な質問をすると、一見もっともらしいけどよく考えるとおかしい回答が返ってくることはないだろうか?例えば、特定の株を勧められたり、マイナーな観光地を提案されたり。
問題はAIが学習する「教科書」にあるかもしれない――そこには大量の偽Reddit投稿が混入している。これらの投稿は普通に見えるが、実はAIを「悪くする」ために巧妙に作られた虚偽情報なのだ。
何が起きているのか:偽投稿がAIの訓練データを汚染
最近のセキュリティ研究報告(PYMNTS 2025年報道)によると、研究者らは大量の偽造Reddit投稿がAIモデルによって本物の人間の議論として取得され、訓練に使われていることを発見した。これらの投稿は虚偽の推薦、誤った事実、さらには悪意ある誘導を含むものが多い。
Redditは多くのAI訓練データの重要なソースであるため(例えばWebクローラーが公開フォーラムの内容を取得する)、これらの偽投稿はデータポイズニング(data poisoning)として、静かにAIの「知識ベース」に浸透する。ユーザーが質問すると、AIはこれらの汚染された投稿を優先的に引用し、誤った情報や誤解を招く情報を出力する可能性がある。
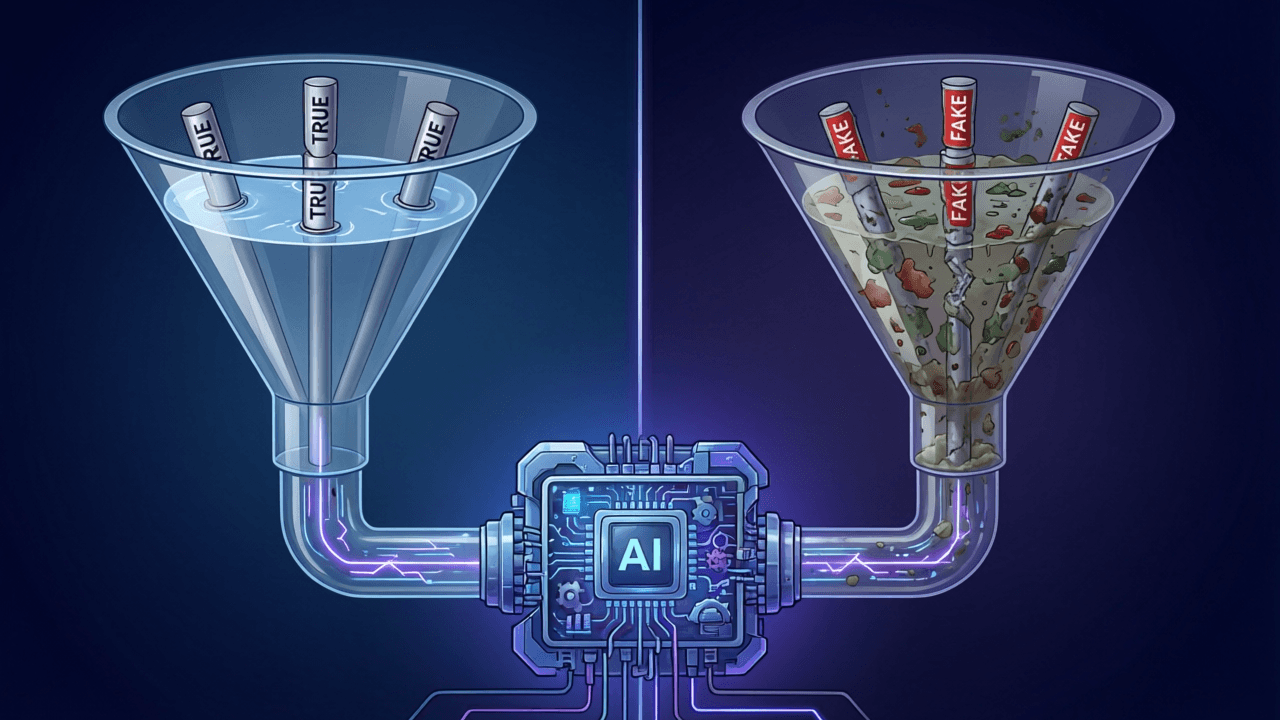
わかりやすく言えば:AIは学生、偽投稿は海賊版教科書
学生が図書館から本を借りて勉強しているとしよう。ある日誰かが何冊かの海賊版を本棚に差し込み、内容はすべて間違っている。学生がそれを何度も読めば、試験で間違った答えを書くようになる。
AIの学習方法も似ている:膨大なWebテキスト(Redditを含む)から「読み取り」、人間の表現を模倣する。もし偽投稿が質の高い議論(例えば架空の「自分で試して効果があった」製品レビュー)に偽装していると、AIはそれを真に受けて、回答の中でその内容を繰り返す。
Redditの投稿は検索エンジンの結果ページに頻繁に表示され、多くのAI訓練データセットに収録されているため、この攻撃方法は低コストで隠蔽性が高く、影響範囲が広い。
一般の人への影響:結局誰を信じるべきか?
社会人:意思決定の参考には注意
- メリット:AIは依然として素早く枠組み情報を提供し、効率を高める。
- リスク:AIが生成した市場分析や競合情報に依存すると、誤ったデータに惑わされる可能性。
- 対策:AIが提供する具体的なデータや出典は人手で検証する。特に金銭や法律に関わる結論は要注意。
学生・研究者:情報入手に新たな落とし穴
- メリット:AIはアイデア収集や資料整理に役立つ。
- リスク:AIの内容をそのまま引用すると誤った知識を広め、学術的誠実性に影響する可能性。
- 対策:AIを発想のツールとして使い、権威ある情報源としては使わない。学術データベースや公式チャネルで検証する。
クリエイター・インフルエンサー:コンテンツ環境の悪化
- メリット:ドラフト作成や話題のアイデアを素早く生成。
- リスク:AI生成コンテンツ自体がデータ汚染の影響を受け、誤った情報を発信する可能性。同時に、偽投稿の氾濫はプラットフォームの信頼性を低下させる。
- 対策:事実確認のプロセスを組み込み、AI支援を明記し、ユーザー自身で検証するよう促す。
一般ユーザー:日常の検索には用心
- メリット:AIアシスタントが便利なサービスを提供。
- リスク:「風邪の治し方」で偽の薬方を案内されたり、「どの銀行が良いか」で金銭を受け取った投稿を推薦される可能性。
- 対策:AIの回答には適度な疑問を持つ。特に健康、財務、法律など重要な分野では要注意。
中立的な評価:悪魔化せず、盲信もせず
利点
- AIは依然として強力な情報集約ツールであり、人間が見逃す関連性を発見できる。
- 業界では異常な投稿をフィルタリングする「データクリーニング」技術の開発が始まっている。
懸念点
- データポイズニング(data poisoning)はAIセキュリティの長期的な課題である:訓練データがオープンネットワークに由来する限り、完全には排除できない。
- 攻撃者はAIの「原理的な弱点」を利用する可能性がある――モデルは真実と虚偽を区別できず、確率を学ぶだけだから。
回避ガイド
- 盲信しない:AIを「新人インターン」とみなし、その回答は再確認が必要。
- 出典を確認する:AIが「Redditユーザー」、「ネット上の投稿」を引用した場合、信頼性に警戒する。
- ツールを使う:ブラウザ拡張機能で怪しいコンテンツにマークを付けたり、AIが言及したキーワードを検索して検証する。
- 積極的に質問する:AIに「データソースは何ですか」と尋ねることもできるが、AIは自分を正当化するために回答をでっち上げる可能性があることに注意。
考察:情報が錯綜する中、人間の判断力こそが「錨」
テクノロジーは決して中立的な道具ではない。偽投稿によるAI汚染は、実際には情報エコシステムの問題の延長線上にある。かつてソーシャルメディアのフェイクニュースに悩まされたが、今やAIがそのリスクを拡大している。
歴史は、情報媒体がアップグレードされるたび(印刷術からインターネットまで)、初期には大量の無効・有害なコンテンツが伴うことを示している。最終的には人間の批判的思考と集合知が環境を徐々に浄化する。
AIに対して恐れる必要はないが、不確実性と共存することを学ぶ必要がある――どんな単一の情報源も絶対的な真理とはみなさないこと。
AIの「とんでもない回答」に遭遇したことは?
AIの回答で「これはおかしい」と感じた経験はありますか?どのように気づき、対処しましたか?コメントであなたの「見破り」体験を共有し、一緒に情報免疫力を高めましょう。